Publications
2026
- ECCV
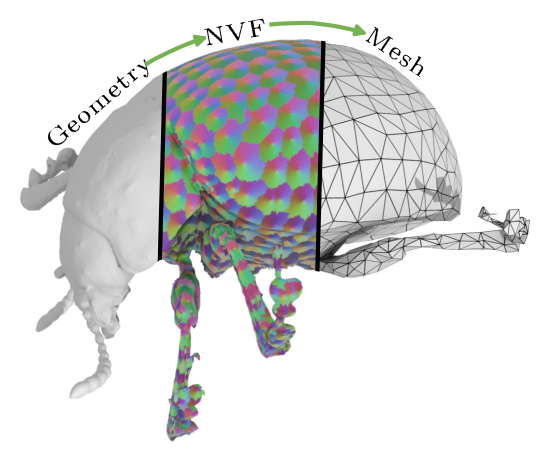 Haoxuan Li, Ziya Erkoç, Daniele Sirigatti, Vladislav Rosov, Lei Li, Angela Dai, and Matthias NießnerIn Proceedings of the European Conference on Computer Vision (ECCV), 2026
Haoxuan Li, Ziya Erkoç, Daniele Sirigatti, Vladislav Rosov, Lei Li, Angela Dai, and Matthias NießnerIn Proceedings of the European Conference on Computer Vision (ECCV), 2026We present TriFlow, a new generative approach for producing compact 3D meshes with artist-like triangle topology directly from input geometry conditions such as signed distance fields. Our key insight is to represent mesh topology as a nearest-vertex vector field (NVF) defined over the surface, where each point encodes its association to the nearest triangle vertex in the local barycentric frame. We train a latent flow-matching model to synthesize this field, enabling topology generation conditioned on the input geometry. To extract a coherent mesh, we cluster surface regions using the generated NVF and guide a constrained quadric error metric (QEM) mesh simplification with topology-aware optimization. This yields output meshes that closely match the input geometry while exhibiting structured, artist-like connectivity. Experiments demonstrate that TriFlow achieves stronger generalization and significantly improved topology quality compared to state-of-the-art learning-based approaches, alongside 90% lower Chamfer Distance and an 8x speedup.
@inproceedings{li2026triflow, title = {TriFlow: Generating Artist-Like 3D Mesh Topology via Nearest-Vertex Vector Fields}, author = {Li, Haoxuan and Erko{\c{c}}, Ziya and Sirigatti, Daniele and Rosov, Vladislav and Li, Lei and Dai, Angela and Nie{\ss}ner, Matthias}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)}, year = {2026}, }
2025
- ICCV
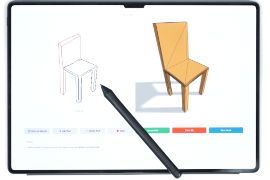 Haoxuan Li, Ziya Erkoç, Lei Li, Daniele Sirigatti, Vladislav Rosov, Angela Dai, and Matthias NießnerIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
Haoxuan Li, Ziya Erkoç, Lei Li, Daniele Sirigatti, Vladislav Rosov, Angela Dai, and Matthias NießnerIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025We introduce MeshPad, a generative approach that creates 3D meshes from sketch inputs. Building on recent advances in artist-designed triangle mesh generation, our approach addresses the need for interactive mesh creation. To this end, we focus on enabling consistent edits by decomposing editing into ’deletion’ of regions of a mesh, followed by ’addition’ of new mesh geometry. Both operations are invoked by simple user edits of a sketch image, facilitating an iterative content creation process and enabling the construction of complex 3D meshes. Our approach is based on a triangle sequence-based mesh representation, exploiting a large Transformer model for mesh triangle addition and deletion. In order to perform edits interactively, we introduce a vertex-aligned speculative prediction strategy on top of our additive mesh generator. This reduces computational cost while maintaining the accuracy of predictions, making it possible to execute each editing step in only a few seconds. Comprehensive experiments demonstrate that MeshPad outperforms state-of-the-art sketch-conditioned mesh generation methods, achieving more than 22% mesh quality improvement in Chamfer distance, and being preferred by 90% of participants in perceptual evaluations.
@inproceedings{li2025meshpad, title = {MeshPad: Interactive Sketch-Conditioned Artist-Reminiscent Mesh Generation and Editing}, author = {Li, Haoxuan and Erko{\c{c}}, Ziya and Li, Lei and Sirigatti, Daniele and Rosov, Vladislav and Dai, Angela and Nie{\ss}ner, Matthias}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, year = {2025}, }
2024
- CVPR
 Dave Zhenyu Chen, Haoxuan Li, Hsin-Ying Lee, Sergey Tulyakov, and Matthias NießnerIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Dave Zhenyu Chen, Haoxuan Li, Hsin-Ying Lee, Sergey Tulyakov, and Matthias NießnerIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024At CVPR 2024, 324 papers were designated as Highlights. These represent the top tier of accepted research, making up just 11.9% of the 2,719 accepted papers, and about 2.8% of the 11,532 total submissions.
We propose SceneTex, a novel method for effectively generating high-quality and style-consistent textures for indoor scenes using depth-to-image diffusion priors. Unlike previous methods that either iteratively warp 2D views onto a mesh surface or distillate diffusion latent features without accurate geometric and style cues, SceneTex formulates the texture synthesis task as an optimization problem in the RGB space where style and geometry consistency are properly reflected. At its core, SceneTex proposes a multiresolution texture field to implicitly encode the mesh appearance, and optimizes the target texture via a score-distillation-based objective function in respective RGB renderings.
@inproceedings{chen2024scenetex, title = {SceneTex: High-Quality Texture Synthesis for Indoor Scenes via Diffusion Priors}, author = {Chen, Dave Zhenyu and Li, Haoxuan and Lee, Hsin-Ying and Tulyakov, Sergey and Nie{\ss}ner, Matthias}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, doi = {10.1109/CVPR52733.2024.01992}, }
2023
- RA-L
 Haoxuan Li*, Yuanfei Lin*, and Matthias AlthoffIEEE Robotics and Automation Letters, 2023
Haoxuan Li*, Yuanfei Lin*, and Matthias AlthoffIEEE Robotics and Automation Letters, 2023The robustness of signal temporal logic not only assesses whether a signal adheres to a specification but also provides a measure of how much a formula is fulfilled or violated. The calculation of robustness is based on evaluating the robustness of underlying predicates. However, the robustness of predicates is usually defined in a model-free way, i.e., without including the system dynamics. Moreover, it is often nontrivial to define the robustness of complicated predicates precisely. To address these issues, we propose a notion of model predictive robustness, which provides a more systematic way of evaluating robustness compared to previous approaches by considering model-based predictions. In particular, we use Gaussian process regression to learn the robustness based on precomputed predictions so that robustness values can be efficiently computed online. We evaluate our approach for the use case of autonomous driving with predicates used in formalized traffic rules on a recorded dataset, which highlights the advantage of our approach compared to traditional approaches in terms of precision. By incorporating our robustness definitions into a trajectory planner, autonomous vehicles obey traffic rules more robustly than human drivers in the dataset.
@article{li2023mpr, title = {Model Predictive Robustness of Signal Temporal Logic Predicates}, author = {Li, Haoxuan and Lin, Yuanfei and Althoff, Matthias}, journal = {IEEE Robotics and Automation Letters}, volume = {8}, number = {12}, pages = {8050--8057}, year = {2023}, publisher = {IEEE}, doi = {10.1109/LRA.2023.3324582}, }